We introduce Vision-Flan, the largest human-annotated
visual instruction tuning dataset that consists of 200+ diverse vision-language
tasks derived from 101 open-source computer vision datasets. Each task is equipped with an expert
written instruction and carefully designed templates for the inputs and outputs. The dataset encompasses
a wide range of tasks such as image captioning, visual question-answering, and
visual understanding. Vision-Flan is built to support various researches and applications in vision-language models, pushing the boundaries of understanding and interaction between these two modalities. Researchers and practitioners can leverage this dataset to advance the state of the art vision-language models
and develop innovative algorithms in a wide range of domains. We showcase an instance for each task on this page.
Data Samples
DATA LOADING . . .
Each instance consists of 3 primary elements: Image, Instruction, and Ouput.
Image: An image that is used as reference when performing the task specified by the instruction.
Instruction: A description or prompt of a task that is executed by the vision-language model.
Output: The expected answer to the instruction given the provided image.
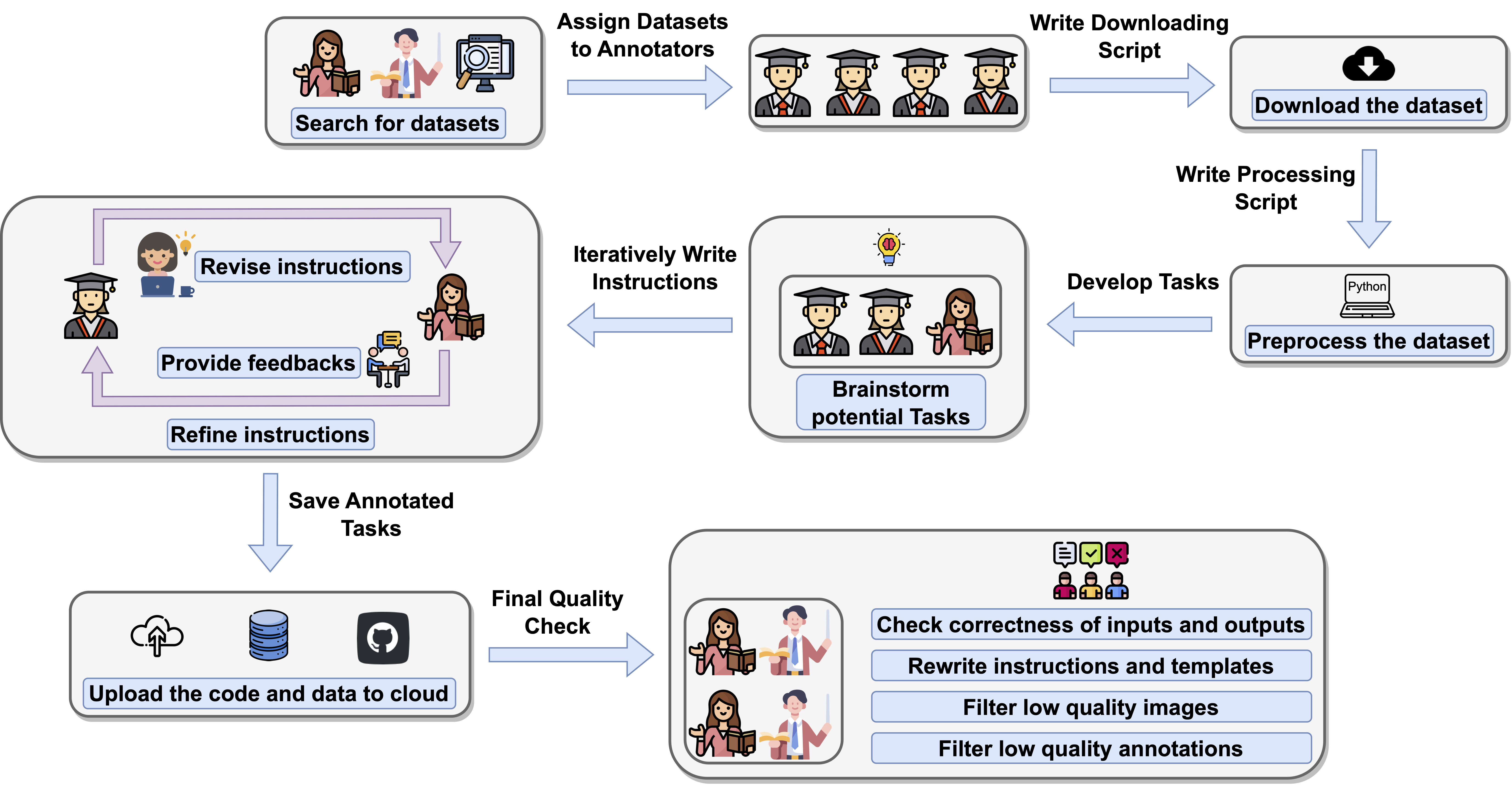
To ensure the coverage and quality of tasks, we proposed an annotation pipeline as demonstrated in the above figure. First, the authors search on the internet to identify interesting vision-language tasks. Second, the tasks are assigned to the annotators and the annotators write download and preprocessing scripts to prepare the data. Once the dataset is processed into the required format, the authors and annotators start discuss potential tasks that can be derived from the existing annotations. Third, the annotators write instructions and templates for each task and the authors provide feedbacks for revising the instructions. This step can repeat multiple times until the instructions meet the requirement. Forth, the annotators upload the processed datasets and instructions to our database. Finally, the authors double-check the correctness of the instructions, images and outputs. The authors also check the grammar and fluency of the instructions. All the annotators are graduate computer science students who have strong background in machine learning and deep learning.
We provide the download links to the annotations and images above. In the annotations file, we merged instructions and templates with original tasks' inputs and outputs. To train a model on Vision-Flan, you can simply download the annotations and images. The annotations file consists of 191 tasks and for each task we randomly sampled 1K instances which should be sufficient for the purpose of instruction tuning. By now we can not release all tasks since some datasets are not allowed to be distributed.
To demonstrate the power of Vision-Flan, we train three vision-language models on 205 tasks in Vision-Flan and use 1K randomly sampled for each task. We finetune the pretrained LLaVa-Vicuna_v1.3_7B for 1 epoch on the mixture of Vision-Flan and LLaVa datasets and name the model vision-flan_llava. We finetune BLIP-2 with Flan_T5_xl as the language model for 1 epochs on Vision-Flan dataset and name the model vision-flan_blip2_xl.
We finetune BLIP-2 with Flan_T5_xxl as the language model for 1 epoch on Vision-Flan dataset and name the model vision-flan_blip2_xxl. We provide Huggingface links to the models above.
Citation
If you use Vision-Flan in your research, please cite the following papers.
@article{xu2024vision,
title={Vision-Flan: Scaling Human-Labeled Tasks in Visual Instruction Tuning},
author={Xu, Zhiyang and Feng, Chao and Shao, Rulin and Ashby, Trevor and Shen, Ying and Jin, Di and Cheng, Yu and Wang, Qifan and Huang, Lifu},
journal={arXiv preprint arXiv:2402.11690},
year={2024}
}
@inproceedings{DBLP:conf/acl/XuSH23,
author = {Zhiyang Xu and Ying Shen and Lifu Huang},
editor = {Anna Rogers and Jordan L. Boyd{-}Graber and Naoaki Okazaki},
title = {MultiInstruct: Improving Multi-Modal Zero-Shot Learning via Instruction Tuning},
booktitle = {Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), {ACL} 2023, Toronto, Canada, July 9-14, 2023},
pages = {11445--11465},
publisher = {Association for Computational Linguistics},
year = {2023},
url = {https://doi.org/10.18653/v1/2023.acl-long.641},
doi = {10.18653/v1/2023.acl-long.641},
timestamp = {Thu, 10 Aug 2023 12:35:59 +0200},
biburl = {https://dblp.org/rec/conf/acl/XuSH23.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Acknowledgement
Vision-Flan dataset is for research purpose only.
Please carefully check the licenses of the original datasets before using Vision-Flan.
We provide the URLs to the original datasets and their Bibtex on this page.
The images and tasks may be taken down at any time when requested by the original
dataset owners or owners of the referenced images. If you hope to take
down any tasks or the images, please contact Zhiyang Xu and Lifu Huang at zhiyangx@vt.edu and lifuh@cs.vt.edu.
Annotators
We want to thank Shivansh Mathur, Ujjwal Maheshwari, Jiayue Lin, Alok Mehandale, Fatemeh Sarshartehrani, Nila Masrourisaadat, and Manasa Reddy Kandula for the work that they contributed to annotating Vision-Flan.